HDF5格式数据集的引入
HDF5格式数据集的引入
Ding Ning1、HDF5 简介
层级数据格式(Hierarchical Data Format:HDF)是设计用来存储和组织大量数据的一组文件格式(HDF4,HDF5)。它最初开发于美国国家超级计算应用中心,现在由非营利社团HDF Group支持,其任务是确保HDF5技术的持续开发和存储在HDF中数据的持续可访问性。
伴随着这个目标,HDF库和相关工具可在自由的类BSD许可证下获得用于一般使用。HDF被很多商业和非商业软件平台所支持,包括Java、MATLAB、Scilab、Octave、Mathematica、IDL、Python、R、Fortran和Julia。可免费获得的HDF发行中包括了库,命令行实用程序,测试包源代码,Java接口,和基于Java的HDF查看器(HDFView)[1]。
当前版本是HDF5,在设计和API上与主要的遗留版本HDF4有显著区别。
HDF5 文件一般以 .h5 或者 .hdf5 作为后缀名,需要专门的软件才能打开预览文件的内容。HDF5 文件结构中有 2 primary objects: Groups 和 Datasets。
- Groups 就类似于文件夹,每个 HDF5 文件其实就是根目录 (root) group’/‘,可以看成目录的容器,其中可以包含一个或多个 dataset 及其它的 group。
- Datasets 类似于 NumPy 中的数组 array,可以当作数组的数据集合 。
每个 dataset 可以分成两部分: 原始数据 (raw) data values 和 元数据 metadata (a set of data that describes and gives information about other data => raw data)。
整个 HDF5 文件的结构如下所示:
1 | +-- / |
2、如何使用 HDF5
HDF5 是一种特殊的数据格式,因此无法被直接打开。需要特殊的译码工具才能读取到真正的数据。一般来说,工具可以分为以下几种:
- 集成工具
- 语言插件
集成工具一般指能够提供:打开、新建、修改、保存。从而实现对文件的管理。但 HDF5 是一种面向大数据的数据格式,用作数据集的场景下比较多。对于语义并不看重,因此集成式的工具并不讨好。
语言插件一般是 HDF5 官方提供文件驱动,其它语言的开源组织进行开发,提供给其它开发者使用的代码库。也有不调用官方驱动,而是自己根据编码格式实现了读写等操作的工具库。我在这里将同时讲解两个方式,我自己使用的是 C++ 语言上社区的工具库 HighFive ,以及 HDF5 官方开源的集成预览工具
3、在 Linux 上使用 HighFive 库管理 HDF5
3.1 HighFive 简介
HighFive 是一个现代的、只有头文件的、 C++11 友好的 libhdf5 接口。
HighFive 支持 STL Vector/string,Boost: : UBLAS,Boost: : Multi-array 和 Xtensor。它处理 C++ 从/到 HDF5 的自动类型映射。HighFive 不需要额外的库(参见依赖项)。
它通过定义(并导出) HighFive 对象的形式,可以与其他 CMake 项目很好地集成在一起。
HighFive 官方文档:https://bluebrain.github.io/HighFive/
3.2 集成 HighFive 至 CMAKE 项目
我是按照官方文档直接安装的,这是官方指导文档,描述的非常清晰:
HighFive 是 HDF5 官方库上层的工具库,因此需要先安装 HDF5 后才能安装 HighFive 。
3.2.1 安装 HDF5
总的说是以下几步:
- 使用系统包管理器安装
- 在一个项目中使用模块
- 使用系统包管理器直接安装
我的系统是 Ubuntu , 直接使用系统包管理器即可安装
1 | sudo apt-get install libhdf5-dev |
- 在 CMakeLists.txt 中引入依赖
示例依赖如下:
1 | cmake_minimum_required(VERSION 3.19) |
也就是通过 find_package 指令引入依赖,并在对应的可执行文件中加入依赖,也就是这几行:
1 | find_package(HDF5 REQUIRED) |
- 测试是否引入成功
官方给出了一段测试代码,如下:
1 |
|
你可以直接将其设置为启动对象并测试。
3.2.2 安装 HighFive
HighFive 是一个远不如 HDF5 官方库热门的项目,因此并没有被大部分系统包管理器所管理。
官方提供了 Spack 上的一键安装,但我没有 Spack , 因此选择手动安装。如果你已经有 Spack 了,那么可以通过 Spack 一键安装,具体可见:
我选择手动克隆并编译,具体操作如下:
克隆
1
2
3
4git clone --recursive https://github.com/BlueBrain/HighFive.git
cd HighFive
git checkout v2.8.0
git submodule update --init --recursive配置、编译、安装
执行下面的命令:
1 | cmake -DCMAKE_INSTALL_PREFIX=build/install -DHIGHFIVE_USE_BOOST=Off -B build . |
第一步遇到了报错
1 | CMake Error at CMakeLists.txt:167 (add_subdirectory): |
定位后是没有 Catch2 。Catch2 是一个测试库, HighFive 使用它进行测试,如果出现了这个报错,可以执行下面这行代码来取消测试,这是官方给出的解决方法。
1 | git submodule update --init --recursive |
- 验证
和刚刚的验证一样,可以通过编写代码进行测试:
1 |
|
在 CMakeLists.txt 中做如下修改:
1 | cmake_minimum_required(VERSION 3.19) |
官方文档没有在这节强调,而是在上节的安装后提了一嘴。
这个安装不是全局安装,因此你需要在对应项目中指定安装的位置,下面是原文:
Later you’d pass the installation directory, i.e. ${PWD}/build/install, to CMAKE_PREFIX_PATH.
所以我们的 CMakeLists.txt 还要加一项修改,找到你克隆项目的目录作为 PWD ,然后拼接得到安装路径,来指明软件/库安装路径前缀
1 | list(APPEND CMAKE_PREFIX_PATH "/home/HighFive/build/install") # 安装路径 |
因此,最后的修改为:
1 | # HDF5 文件管理工具构建 |
4、在 windows 上使用 hdfview 预览数据集
直接下载官方提供的预览器。下面是官网:
安装后随便打开一个HDF5文件,即可看到文件的组织结构。我这里拿 fashion-mnist-784-euclidean.hdf5 这个数据集来举例,打开后可以看到是如下图的界面:
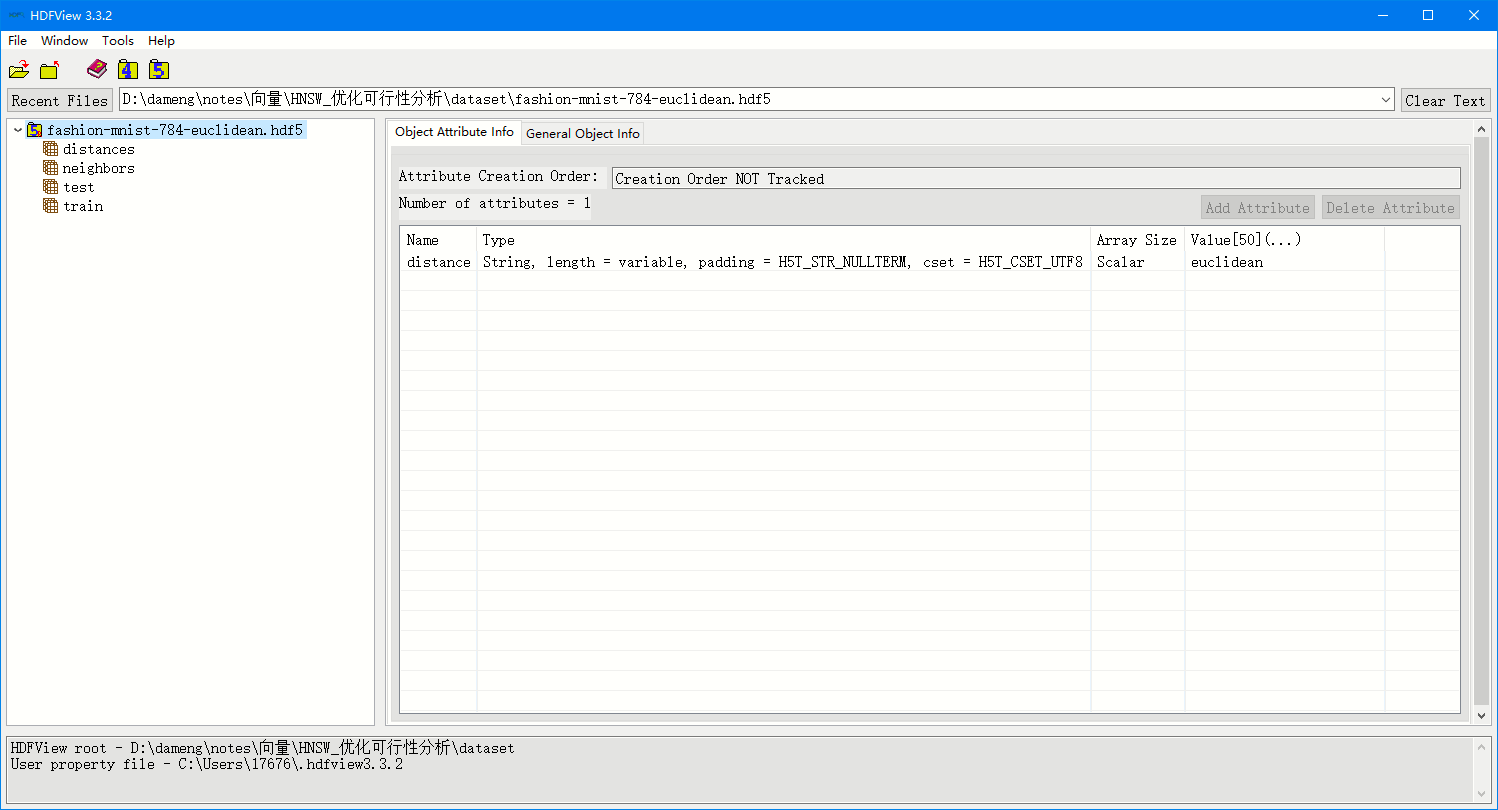
这里展示了一行数据,这是本数据集专有的 距离算法 的信息。这行的四个列分别表示:数据名称是 distance ,数据在 HDF5 中的存储格式是 UTF8 + 变长 + String + 以HDF5的空格分隔符分割 的格式存储的;数组长度是标量;数组内容是 euclidean 。
翻译一下,其实就是存储了一个名为 distance 的字符串,内容是 euclidean 。这其实是我们这个大数据集的一些特殊信息,这个数据集是一个向量相似度计算的数据集,所以需要特意声明这个数据集适合的距离计算公式,也就是 euclidean 。

这部分的内容是独立存在的,并不属于任何一个子数据集。
接着我们可以看到左侧有若干个数据集,如下图:

这是我们真正要使用的数据集,其中包含了四个数据集。任意点开数据集,可以发现并没有直接显示出来数据,但是我们可以通过双击数据集名称来预览数据集,以及通过点击 General Object Info 来阅读数据集的各种信息。我这里拿 test 数据集来举例:
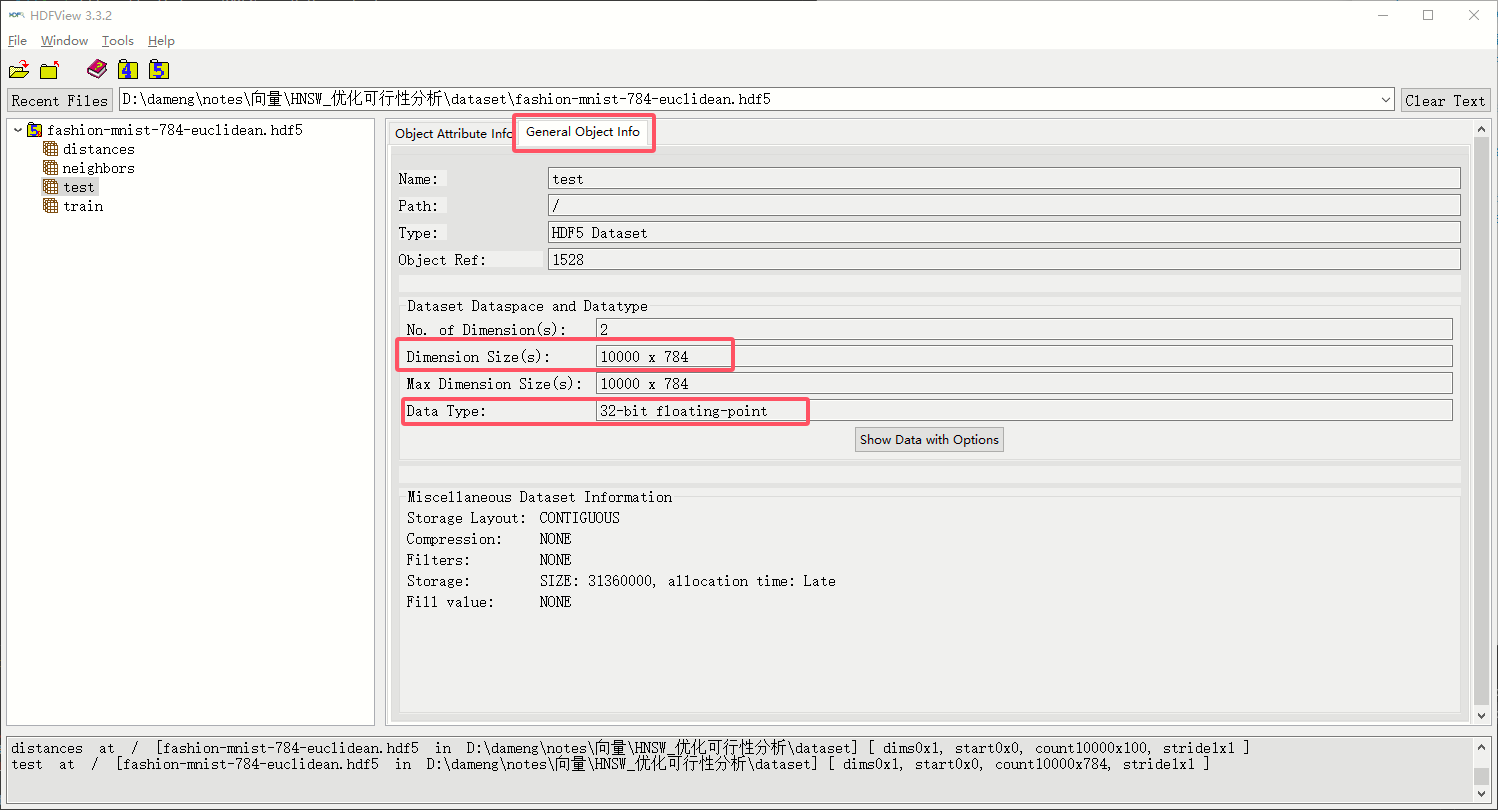
General Object Info 后可以阅读数据集的对象信息,最重要的是核对两项,维度 (demension) 和 数据类型 (data type)。维度数据是 10000 * 784 ,数据类型是 32bit float ,接着我们再去核对数据集官方的介绍:

PS:我的数据集来自 ANN-Benchmarks 项目
项目地址: https://github.com/erikbern/ann-benchmarks/tree/main
可以看到,是和官方描述完全一致的, 10000 * 784 中的 784 是单条向量的维度, 10000 是测试向量的数量。以此为例,你能够读懂这个数据集中每个 item 的含义了。
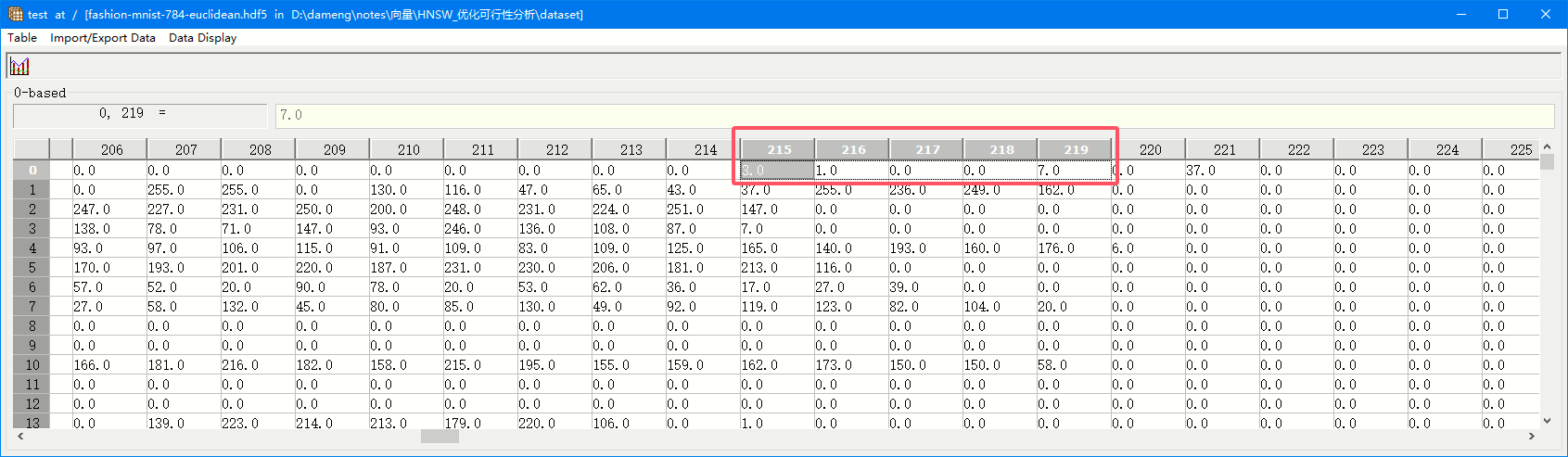
双击数据集名称后,可以直接预览数据集的具体数据:
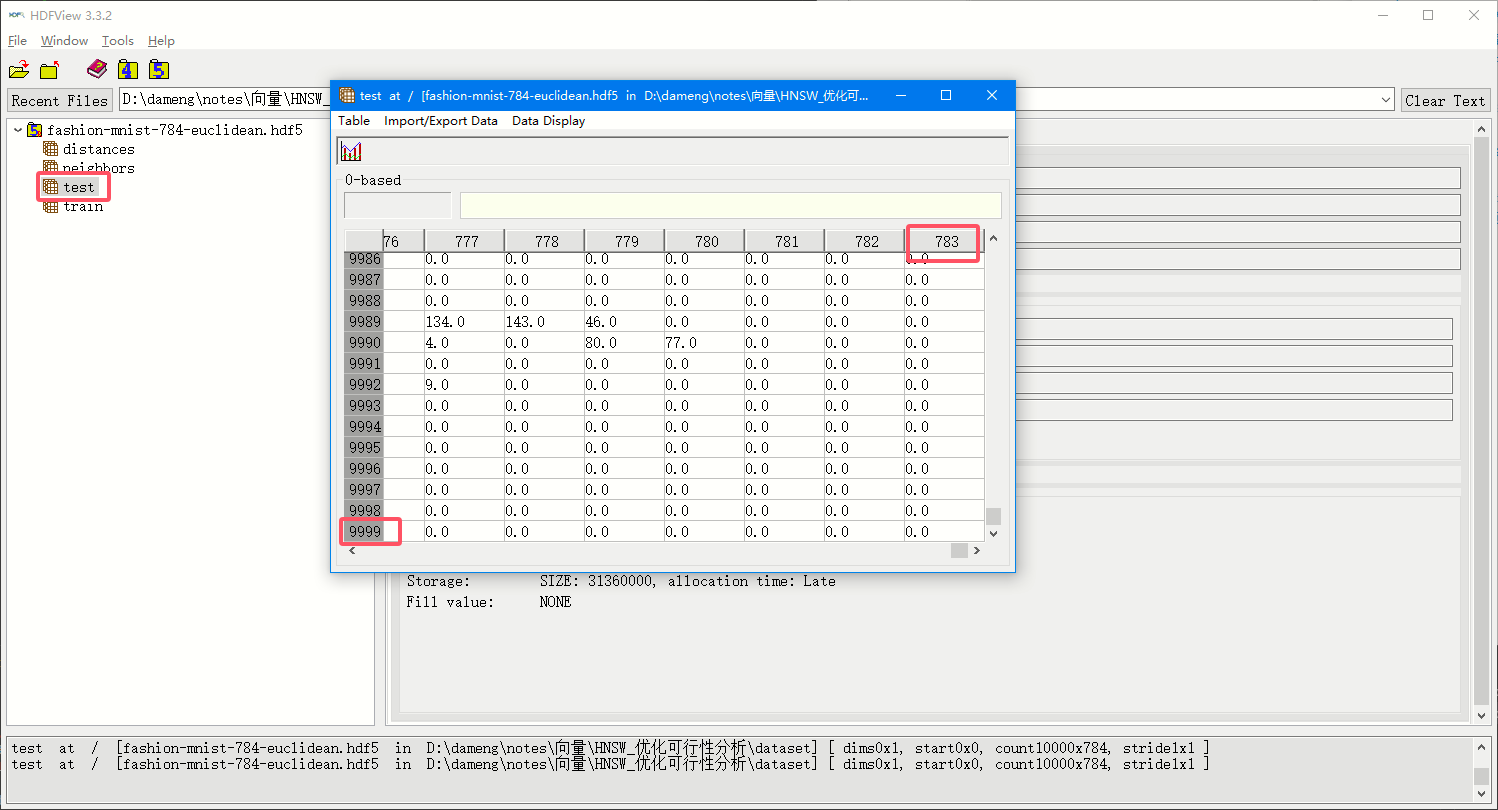
可以看到和刚刚 General Object Info 中展示的一致。
5、在代码中解析使用数据集
通过上面步骤 4 ,我们预览了数据集,确定了数据集中数据的格式。以 test 数据集为例,我们知道了该数据集是一个 2 维的 float 数组。(32 bit 浮点数在 c++ 中是4字节的单精度浮点数 float ,数据是 10000 * 784 代表数据集是二维的)
因此我们需要查询我们的代码工具库,看看如何才能将数据解析成对象来使用。下面是我找到的官方示例,实例中的数据是一个 double 类型的二维数组,与我们的要求一致。
https://github.com/BlueBrain/HighFive/blob/master/src/examples/select_partial_dataset_cpp11.cpp
因此,在对代码进行一定程度的修改,就可以使用了。我的代码如下:
1 |
|
在输出行打个断点,只输出一个向量,可以看到结果如下:
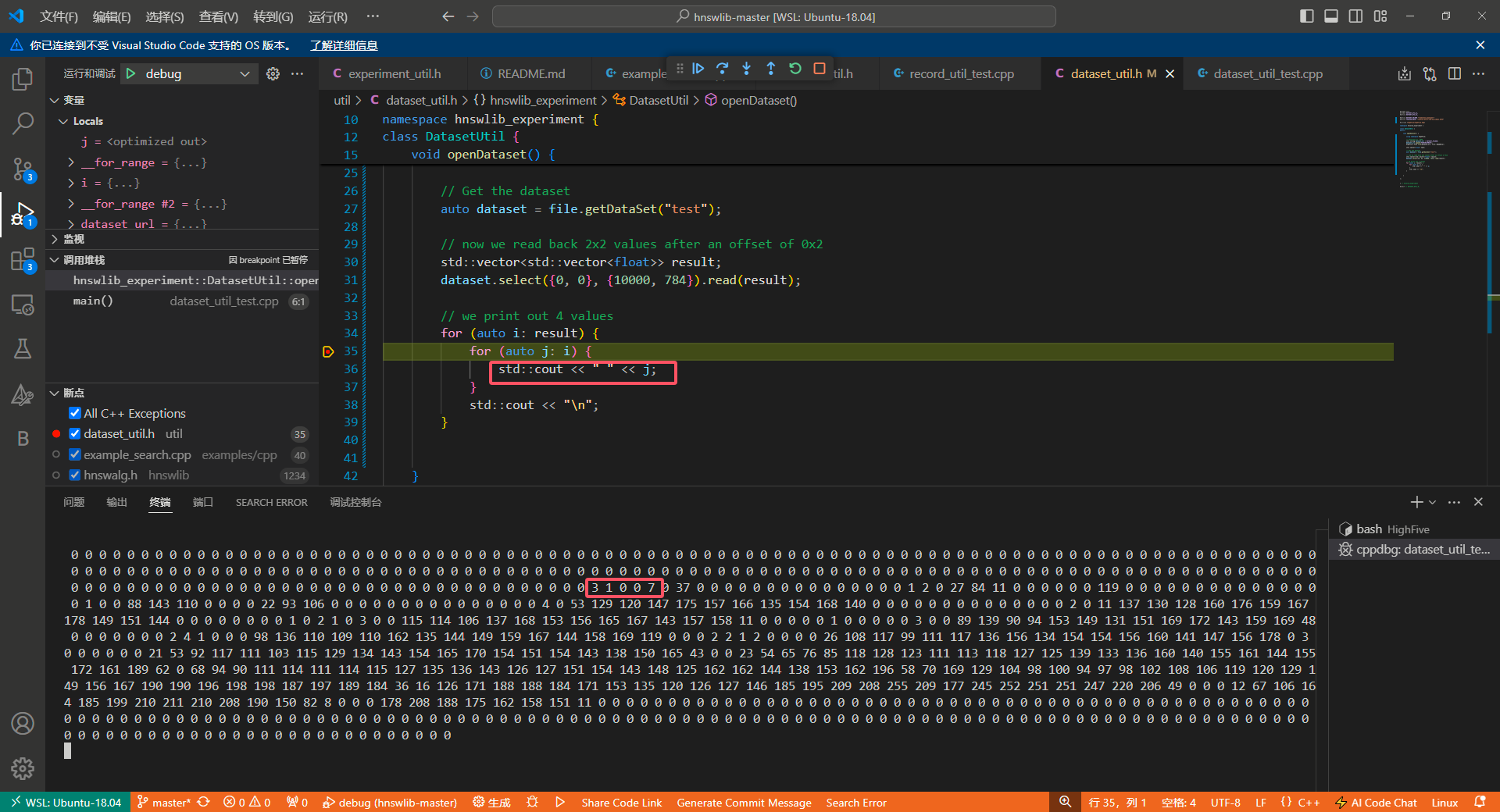
我们打开数据集预览,核对一下,发现无误:
结语
到这里,我们的教程就结束了。希望能帮你节省一些时间。
授人以鱼不如授人以渔,多查阅官方文档和社区,增强自己解决问题的能力才是王道。我的配置教程全部以官方文档为主线,在遇到问题时查询 Google 。

