从一道面试题开始-Java新建线程启动一次IO都做了什么
从一道面试题开始-Java新建线程启动一次IO都做了什么
Ding Ning前言
笔者在前几天的一次面试中被面试官问到了一个很发散的问题,Java 新建线程启动一次 IO 都做了什么?
这个问题想简单的话,两三句话就说完了。但是这是我们展示自己知识体系的好机会,加上我认为当时自己的回答不太健全,所以我们从头捋顺一下相关知识点,将它们串联起来。
本文阅读的 java 源码为 jdk-23.0.2 ,版本较新,可能会涉及新版本特性。和老版本 1.8 的源码布局稍有不同。这是我们选择的 openjdk 源码仓库:
java源码的目录为:
jdk/src/java.base/share/classes/java
,这里存放了很多重要的基础包。
1、启动一次 IO ,都做了什么?
1.1 JAVA 的 IO 工具类
要确定都做了什么,我们首先要限定我们IO方法的具体调用路径。
众所周知, java 的 IO 分为 同步IO 和 异步IO 两种。 java.io 包中为我们提供了 同步IO 工具,而 java.nio 包中为我们提供的是 异步IO 工具。
所谓的 同步与异步 指的是在 从发出IO指令到IO内容可用 这个过程中 启动IO的线程的运行状态。在 同步IO 中,线程在发出 IO 指令后就自动地进入了等待阻塞状态,直到目标数据准备好(或者说全部加载到了内存中的某个可以被读取的位置)时,线程才会被唤醒,执行下一步的处理操作。而 异步IO 中,发出IO指令的线程不会被自动阻塞,而是可以继续执行某些工作(当然,这些工作必须是与所读取数据无关的,或者你也可以手动地阻塞掉它们)。
清晰理解了 同步与异步 概念后,我们可以看看这两个包都提供了哪些工具类,然后用这些工具组装一个启动 IO 的工具函数。
1.1.1 java.io
当我们打开 java.io 包后,可以发现这个包里的类一眼望不到头,但事实上我们可以将其归类为几个部分:
Stream 代表的字节流 IO 工具
以及 Reader 和 Writer 表示的 字符流 IO 工具
以及其它更多的接口、工具类、异常。
这里不得不提一嘴的是 java 的 字符流 工具。字节流与字符流其实都是一个基于流式数据的上层封装。所谓的流式数据,是 2进制 数据的通用表示方法,也就是一串 0101010101 。把这种序列从一端开始顺序读取的过程,就像一条单向的河流,一去不回。
而我们都知道,现代二进制计算机的最小电子元件是一个 01 开关,也就是一个 bit 。但是由于硬件的大幅进步,每个芯片、外存、上的01开关数量过于巨大,仍然一次性处理一个 bit 的效率实在是太慢了。所以现代计算机往往采用 4bytes 对齐的方式同时批处理 32个 bit 或者 64 个 bit。
IO 也是一样,现在计算机的 IO 一般都是通过总线批量进行若干个 bit 数据的 IO ,一次性能够向处理器输送的数据也是远远大于 1 bit 的。所以为了最高效地利用输送过来的全部数据,IO的最小处理单位往往是远大于 1bit 的,也就是我们常说的批处理思想。
在这个思想上层,高级语言往往会提供各种粒度的批处理工具。java 提供的工具便是 字节 和 字符 流。字节流的处理单位是 4bit 也就是 1字节,它的处理粒度较细,适合高性能的编解码运算。比如常见的数据的二进制序列化和反序列化功能:
假定我们要自行编写一个能够持久化存储 32bit 的 int、32bit 的 float、32bit 的 unsign int 三种类型数据列表的序列化和反序列化器。能够将下面这类序列持久化并在下次启动程序时复原成一个列表:
int 2
float 2.22
un int 22
int 88
float 1.2
一个简单且高效的序列化协议是:
| 1byte 反序列化为 无符号正整数,用于存储共有多少个数据 | n byte 首部,分别用于代表每个数据的类型,由于只有三种类型,每个数据的类型只需要占用 2bit 即可| data1 2 | data2 2.22 | data3 22| ...... |
这样,存储空间几乎没有任何浪费( n byte 首部 可能会存在一些浪费)。
明白了字节流的优点,我们自然会产生一个问题,为什么 java 会维护一个官方的字符流工具呢?都用性能好的字节流不行吗?
要回答这个问题,我们要从 java 的历史开看。 java 是一个 web 原生的语言,其重要应用场景就是网络处理,或者说作为网络服务器开发语言。因此, java 天然地与文字处理有密切的关系。文字处理中重要的编码协议 unicode 是变长的,所以人手再写一个编码解码器太蠢了,又因为 java 已经拥有了字符类 char ,写一个自动编解码工具的工作量不是很大,因此 java 选择将字符处理工具直接集成在了工具包里。
事实上, Reader 和 Writer 的本质还是在 字节流 工具上封装一层解码编码工具,下图是 FileReader 的重要构造函数:
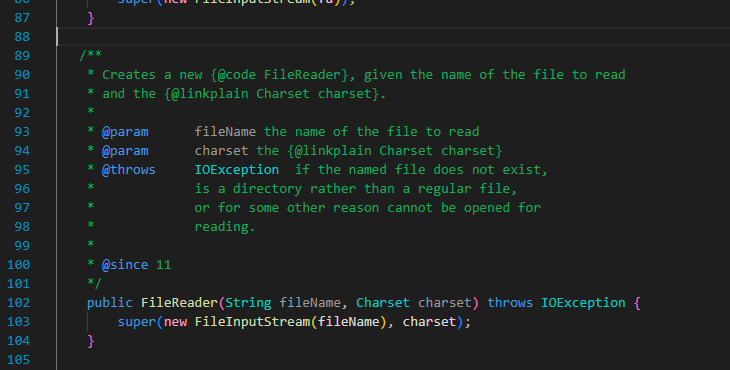
可以看到其构造函数直接 new 了一个 FileInputStream 对象作为描述符传递进了父构造函数(InputStreamReader)
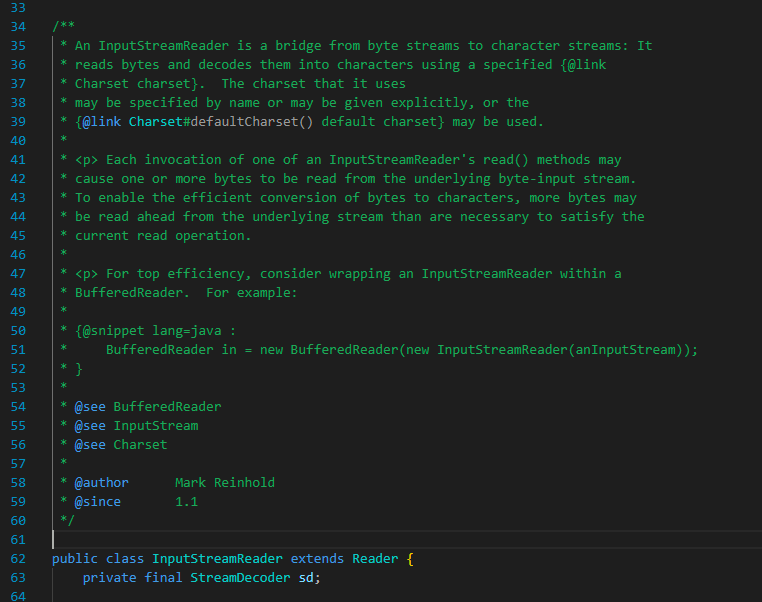
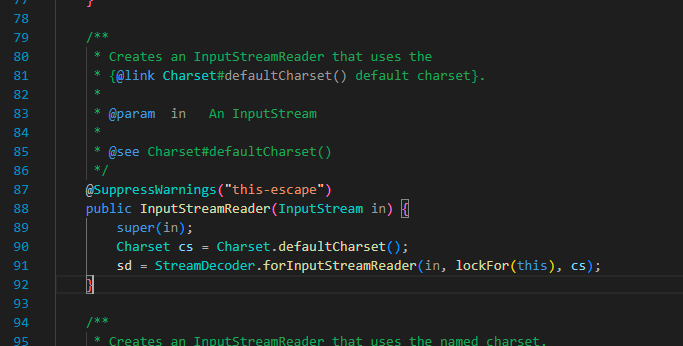
而在 InputStreamReader 的构造函数中,也就是上图,我们可以发现这里做了两个操作:1、设置了对应编码集的解码器;2、缓存了作为参数传递进来的 InputStream 实例对象。
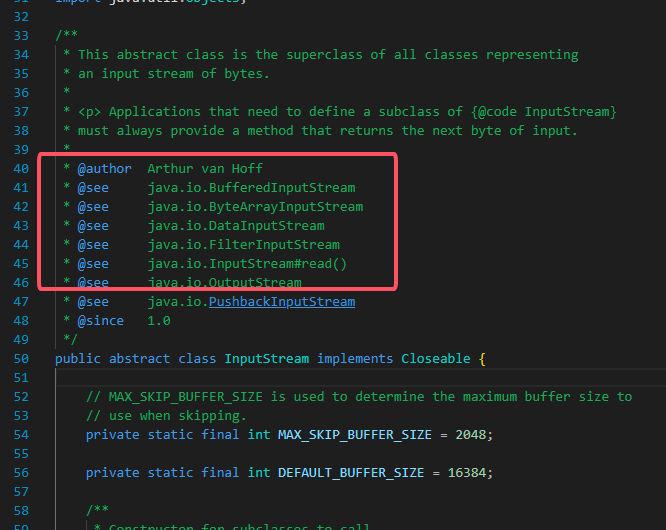
InputStream 是一个父虚类,它是上面红框里面所有类的父类,我们随便挑一个实现类来阅读下:
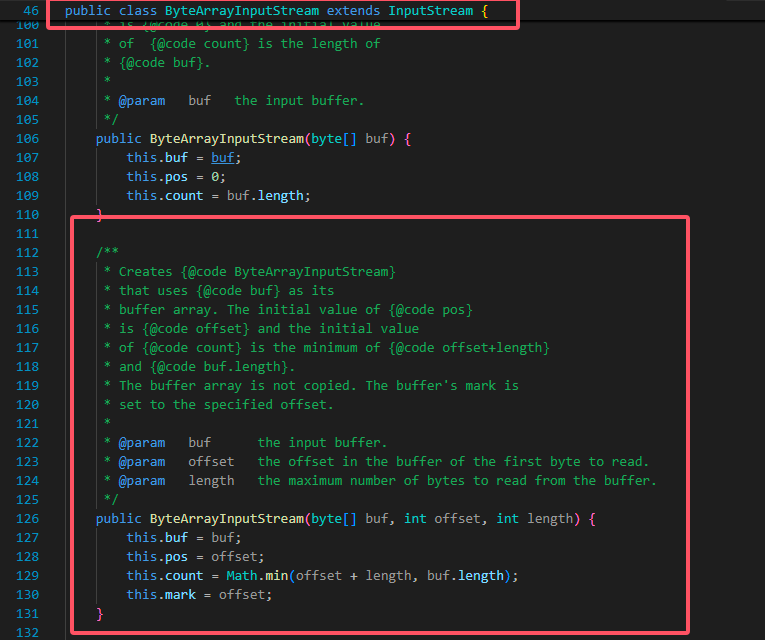
可以看到,我们选择的 ByteArrayInputStream 实际上就是一个把 byte 数组的读取行为封装为字节流的工具类。
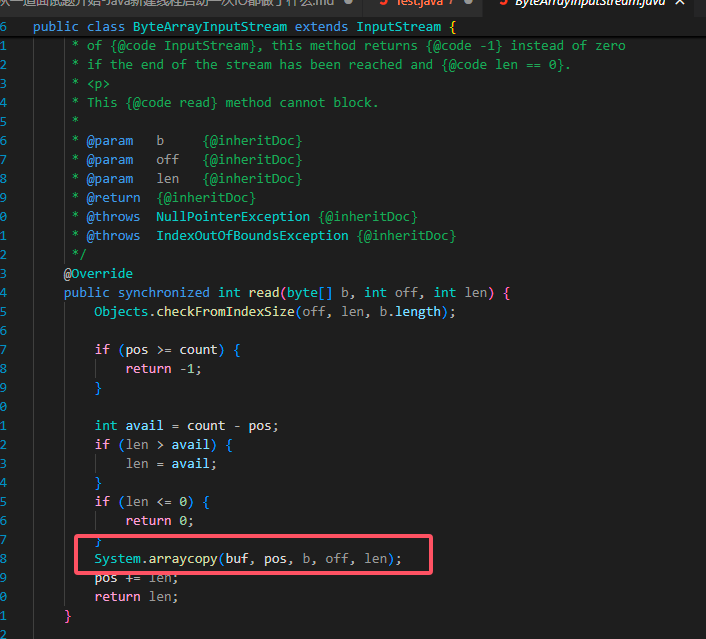
而 ByteArrayInputStream 的 read 函数也是简单的把 byte 数组的读取行为转为了对某些字节的 copy 操作而已。
我们已经明白了无论是 字符流 还是 字节流,其底层的编解码都是以 字节流 实现的。接着,我们随便 new 一个 FileInputStream ,调用其 read 函数,把文件的前10个字节拷贝到内存中的数组 cbuf 中,供后续操作使用:
1 | // 创建文件对象,包含了文件在操作系统中的描述符 |
我们会发现它的注释中对特意描述了阻塞行为:
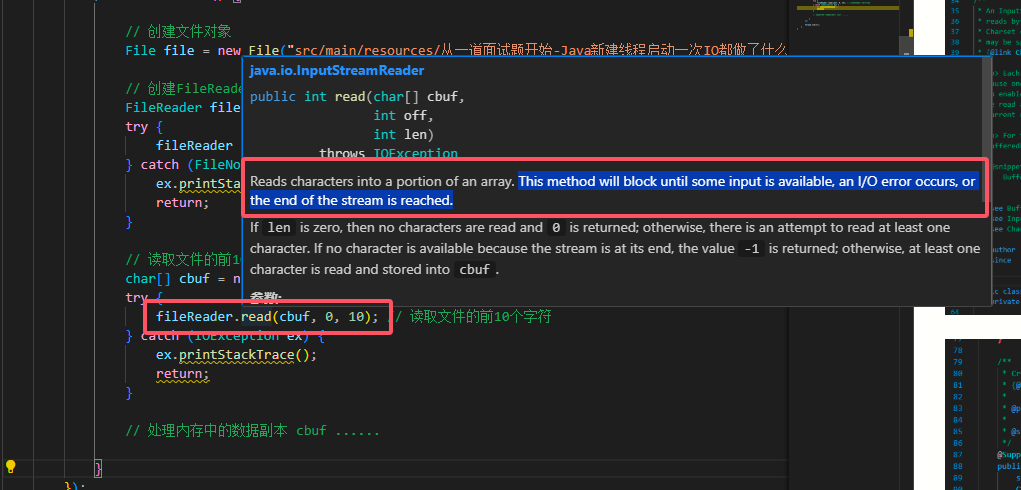
这也是 java.io 包中 IO 工具的特性,在数据没准备好之前,也就是 FileInputStream.read(cbuf, 0, 10) 没有完成之前,我们这个线程都是阻塞状态的。说到这里,可能有的同学还是不明白,到底是哪里 sleep 了还是 await 了才造成了当前线程的阻塞呢?
我们接着来继续阅读 read 函数:
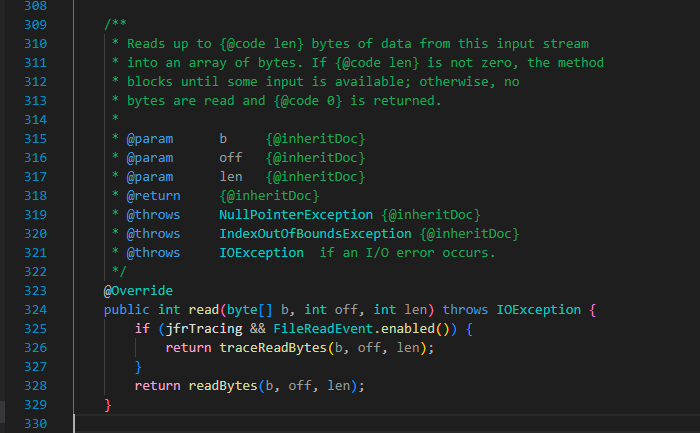
read 函数有两个分支调用:
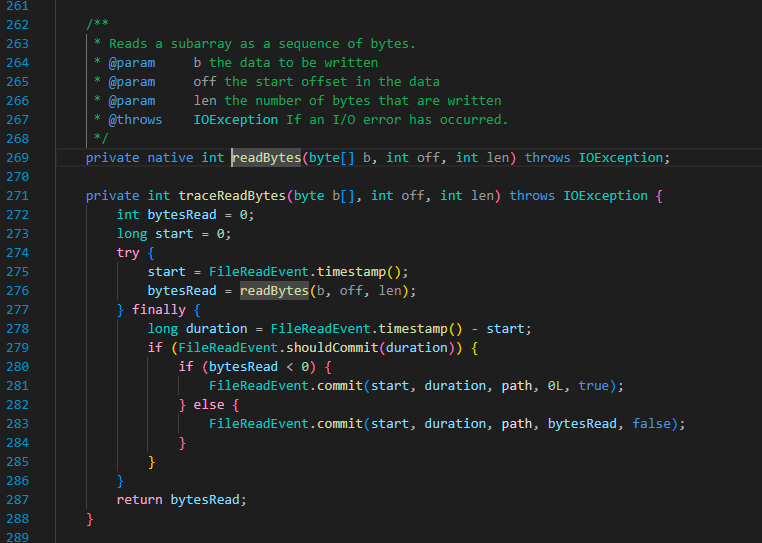
可以看到两个分支最后都是调用了 readBytes 实现的读取数据。但这里 readBytes 直接用一个 native 修饰符阻断了阅读。native 也是八股里面的老朋友了,即 jvm 根据不同平台实现的本地方法,使用的具体语言都是使用 c/c++ 。下面是一些相关资料,不了解的朋友可以拓展阅读一下:
Java安全详谈-JNI 底层分析 https://qftm.github.io/2022/05/29/Java-JVM-JNI/
Java IO 学习(五)跟踪三个文件IO方法的调用链 https://www.cnblogs.com/darcy-yuan/p/17591027.html
自己实现一个 native 方法 https://houbb.github.io/2020/07/19/java-basic-06-native
在 Windows 平台上,实现 native 方法的一个简单做法是,通过 javah 工具生成包含 native 方法的 class 文件对应的的本地方法 .h 头文件,实现后,编译成动态链接库文件.dll ,就可以直接直接在 java 代码中加载,如下面的 java 代码:
1 | /** |
IO_Read 是 native 方法实现中调用系统接口的宏定义,在 C/C++ 中,宏是一种编译工具,常用的场景是根据不同操作系统,编译相同函数的不同版本,也就是我们下图中的 windows 与 unix 系统两个版本的相同 native 方法的不同实现:
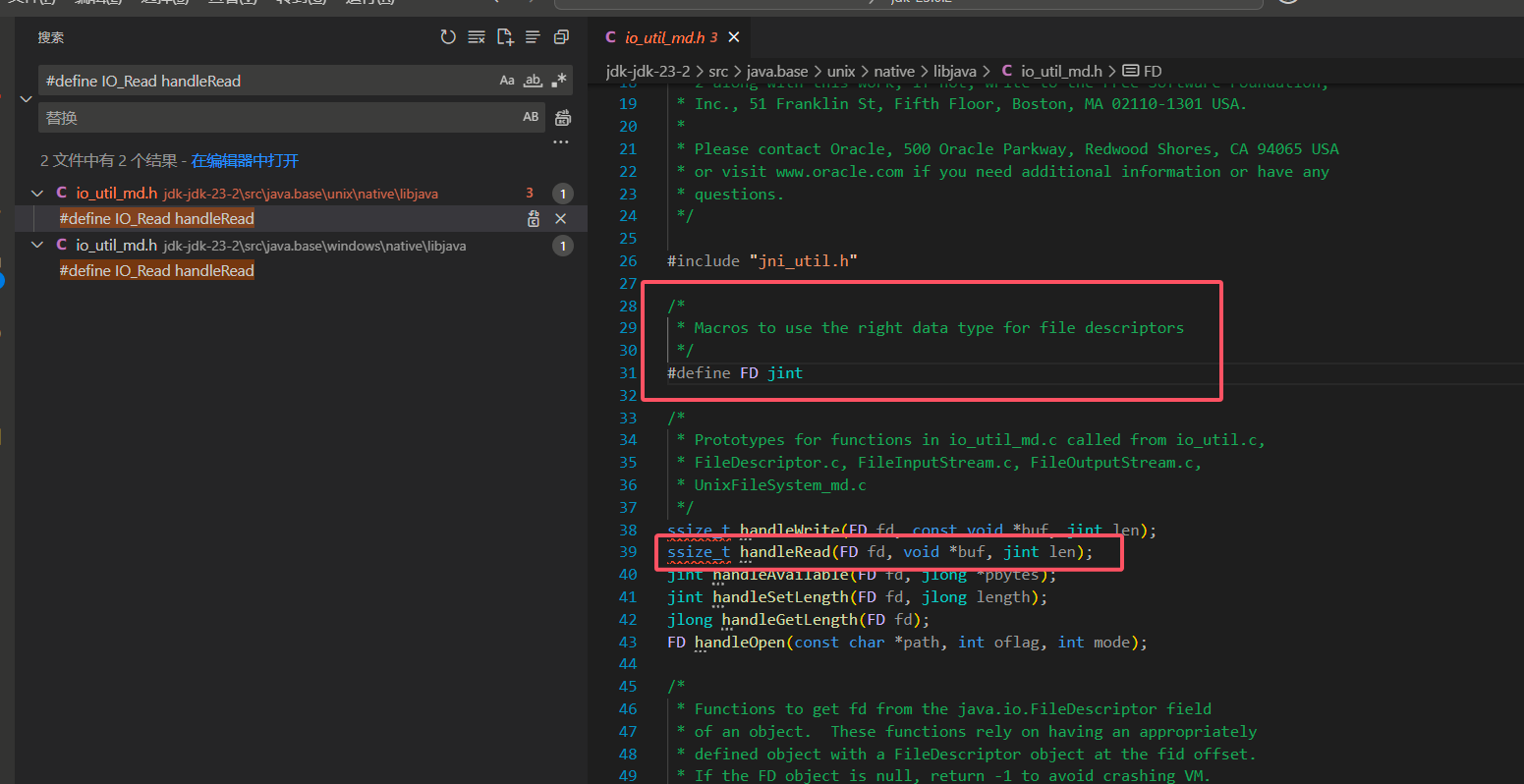
由于我们的 java 程序一般都部署运行在 Linux 服务器上,所以这里不深入阅读 Windows 的读文件接口都做了什么,只以 Linux 为例。上图中红框圈出来的部分是两个重要部分, FD 是操作系统的文件描述符,而 下面的 handleRead 函数定义,在 头文件的 .c 文件中实现了:
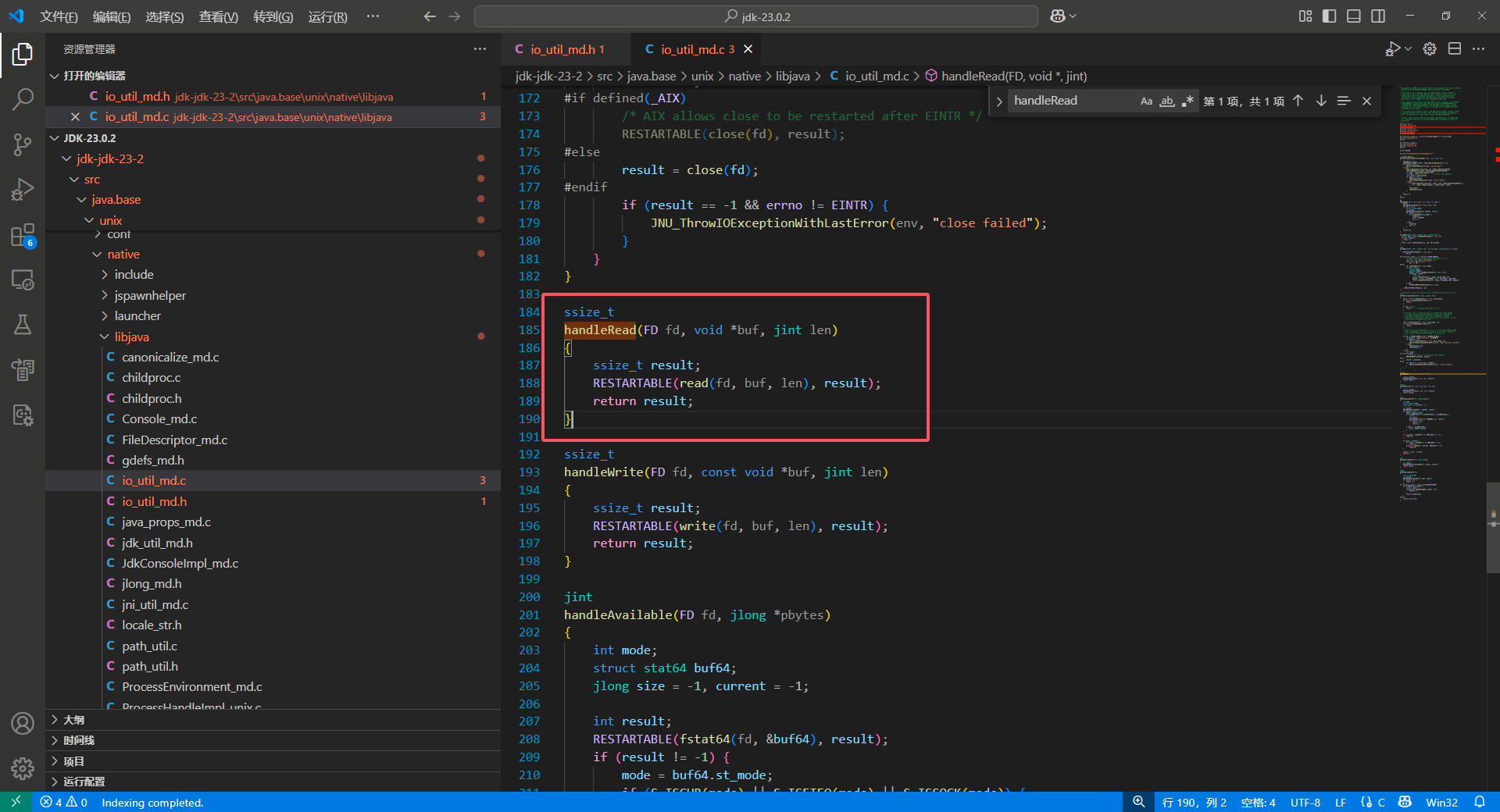
可以看到, handleRead 实际上就是用 宏RESTARTABLE 包装了 read(fd, buf, len) 函数。
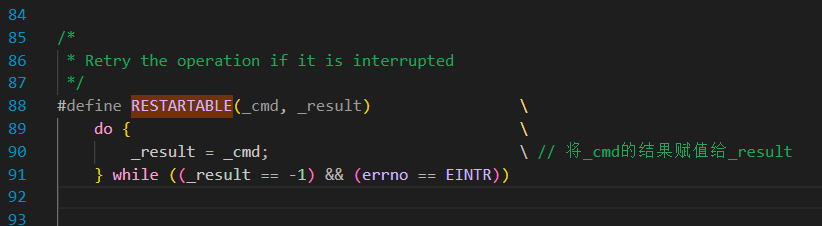
宏RESTARTABLE 要做的不停地执行第一条指令,把其返回结果赋值给 result 。而我们这里的 result 是用户内存空间中的 ssize_t 对象,这里的返回值其实是 Linux 内核函数的返回结果,我们接下来深入阅读 jdk 的原生 native 方法 handleRead 中,引入的 unistd.h 头文件中定义的 read(fd, buf, len) 函数到底在做什么:
1 |
|
要阅读 Liunx 内核源码,我们便无法在 Windows 的环境下方便地阅读(实际上可以通过下载 Linux 内核代码,将源码包添加到 VSCode 的 include path 中实现动态依赖解析。但对我而言太麻烦了,有一台自带源码的 Ubuntu 为什么还要折磨自己呢,笑)。如果不想阅读 Linux 内核,你也可以选择阅读 Windows 的 IO 接口,下两图是笔者在 Windows 上直接阅读 ReadFile 接口的示例:
说远了,我们再回到 Linux 的 read(fd, buf, len) 函数,直接读源码其实还是相对复杂的,但我们可以很多社区文档以及官方文档下手,如:
【高级编程】Linux read系统调用 https://cloud.tencent.com/developer/article/1058901
https://zhuanlan.zhihu.com/p/608617884
https://wuxiaoleisuperlei.github.io/2017/12/09/read/
这里强推第一篇文章以及下面这篇文章:
操作系统用户态和内核态之间的切换过程是什么_用户进程从用户态切换到内核态 https://cloud.tencent.com/developer/article/2131452
简而言之, read 函数是一个 Linux 的系统调用,也就是说,接下来执行的这段代码是涉及到操作系统管理的资源的。因此, Linux 会触发 线程/进程 的上下文切换,把线程的上下文从 用户态 提升至 内核态 ,从而执行内核态权限的代码 sys_read() 发出真正的 IO 。我们把整个调用流程用下面的三个步骤表示:
1 | 用户c/c++代码 -> read(fd, buf, len) -> sys_read() |
其中 上下文切换便发生在
1 | read(fd, buf, len) -> sys_read() |
这两个步骤中间。
完成了上下文切换,当前线程的上下文就变成了 内核态 ,接着便会进行一系列的文件内容查找。我们这里用博客 https://cloud.tencent.com/developer/article/1058901 中的一张图来进一步分析这个过程都做了什么,详细的就不赘述了:
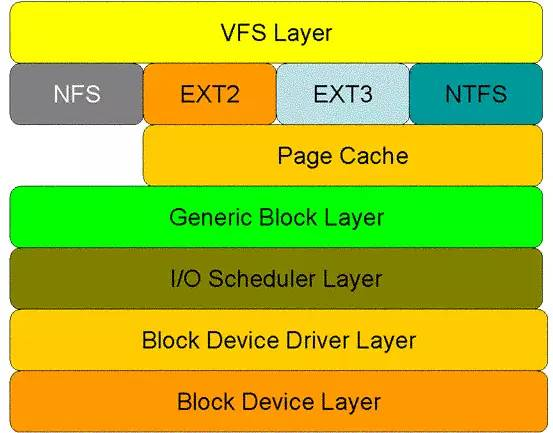
从图中看出:对于磁盘的一次读请求,首先经过虚拟文件系统层(vfs layer),其次是具体的文件系统层(例如 ext2),接下来是 cache 层(page cache 层)、通用块层(generic block layer)、IO 调度层(I/O scheduler layer)、块设备驱动层(block device driver layer),最后是物理块设备层(block device layer)。
但是这里我必须要额外说一句的是 page cache 层。 page cache 是 Linux 的读缓存层,它会适当地把一些文件的内容缓存在内存中,以避免每次读取时都启动 IO 。我们常用的内存查看指令 free 就展示了 page cache 的当前大小,下图中我的主机就有 33G 内存都用做了 cache (实际上这里同时包含了读写缓存,在 Linux 中读写缓存的意义是不同的。读缓存是将外存的数据放在内存中,减少不必要的IO;而写缓存是将需要写回外存的数据缓存在内存中,供批量写回使用,减少频繁的写入操作带来的额外消耗,尤其是类似对同一块数据进行频繁修改的情况)。

因此, sys_read 实际上会优先查找 page cache 中是否有目标块,并不一定会直接启动外存的 IO 。
清楚了 进程线程上下文(用户、内核态) 的概念,我们接下来要关注的是数据到底拷贝了几次?
深入理解 Linux的 I/O 系统 https://zhuanlan.zhihu.com/p/427193419
这里我推荐阅读上面的这篇博文,引用他的一张图:
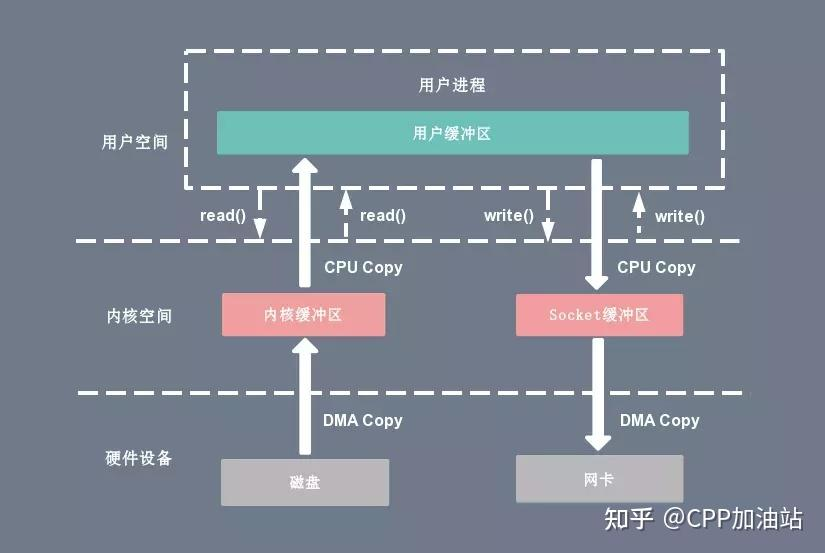
实际上, read 函数是走 缓存 的,如果 缓存 没有,cpu 会首先将数据从磁盘加载数据到内核空间的读缓存(Read Buffer)中,再从读缓存拷贝到用户进程的页内存中。这个过程中,出现了一次 DMA COPY,并不是由 CPU 负责。DMA 拷贝未完成之前, 线程/进程 会被阻塞,直到 DMA 拷贝完成。接着 CPU 会启动第一次拷贝,把数据从内核态空间 读缓存 拷贝到用户态空间的指定位置,即我们调用 read 函数时传入的地址,这里出现了第一次 CPU COPY 。此时,用户态空间的制定地址处,已经存放好了我们要读取的若干字节内容, read_sys 的责任就结束了,因此,线程还会从 内核态 切换到 用户态 ,然后继续执行用户编写的 c/c++ 代码。在我们的 native 方法中,执行的便是宏编译后的代码,即:
1 | ssize_t |
我们再把上面的过程做一下复述,如果只是准备面试,背下来这段就可以了:
1 | 1、当进程发起一个读取操作时,如果数据不在缓存中,会发生缺页中断,然后进程会被阻塞,进入睡眠状态,直到数据准备好。 |
我们这里忽略了 read 函数的返回值是怎么从内核态 sys_read 一层层传递过来的,想了解的同学可以进一步学习 进程上下文切换 会做的栈保存等机制来思考这个问题。
读到这里,我们其实已经把 FileInputStream.read() 函数的全流程调用栈读完了。回想一下,这里面包含了很多知识点:
1、字节流、字符流 的区别和关系,它们的优点
2、native 方法是怎么实现的
3、如何阅读编写 一个 native 方法,以及 readBytes 这个 native 方法到底调用了什么
4、Linux 中 read() 函数都做了什么,为什么调用它的 线程 or 进程 会被阻塞
5、read() 函数触发的系统调用中,上下文切换是为什么
6、Linux 的文件缓存机制, read() 函数和缓存层的交互关系
我们在后续的实现中,同步 IO 就直接选择简单的 FileInputStream 进行讲解,原因是 FileInputStream 的内存拷贝不涉及到解码,是直接对二进制流的全拷贝,性能相对较高且更接近底层,不用讲解上面封装的应用功能。
1.1.1 java.nio
阻塞 IO 的模型非常简单。我们在上面的小节里面详细地阅读了阻塞 IO 为什么是阻塞的,其核心原因是阻塞 IO 直接把当前的线程作为 IO 线程,通过在 IO 过程中动态地升级线程的上下文等级实现读取数据至内存。这个过程中,待读取数据的目前状态(是否已经被加载到 os page cache,是否已经完成了 os page cache 到 user memory 的拷贝)是被封装了起来的,其对程序员是透明的。
这种处理逻辑是相当简单的,能够应付几乎大部分的应用场景,但与简单相对的是灵活性不足,这种不足主要体现在一条线程只能同时使用或处理一条 IO 流。如下面的两段代码:
1 | public class IOTest { |
上面的这段代码的功能是读取一个输入的文件名,把文件的前十个byte读取进内存,然后使用这些数据做一些操作。这个功能被死循环包括,因此除非程序被强制杀死,会一直持续这项任务。值得我们关注的是,每次输入一个文件名,上面这段程序都会在处理完上一个文件后,才能够读取下一个输入。因此,上面这段程序只能使用 CPU 中的一个运算核心,即使 CPU 有多个内核。我们可以认为,此时系统的处理瓶颈在于处理输入的速度。多核 CPU 很明显可以让我们同时读取多个不相干文件并同时进行处理,但我们的单线程阻塞机制导致我们无法有效地利用多核。
上述功能可以被理解为数据库 select 方法的一部分,select 可以粗略地划分为 接收 sql 并解析,读取本地文件并运算,返回结果 三个步骤。我们将客户端与服务器的概念简化为命令行的人工输入,并忽略了输出功能,只关注 输入 & input 这两个环节。
1 | public class IOTest { |
为了提高系统的吞吐速率(或者说QPS),我们自然地想到了同时处理多条输入的优化方法。也就是接收参数的线程不阻塞,它只负责启动读取线程,这样,每个输入都能被立刻响应。具体实现可以阅读上面的这段代码。这样的实现方式可以很容易地跑满 CPU ,无论有多少个核心,我们都可以通过新增无数个线程把 CPU 占满,让每个线程在被短暂阻塞期间,CPU 都有一个其它的线程在跑。这大大增加了我们这个函数的吞吐率,把性能瓶颈从:
1 | fileInputStream.read(cbuf, 0, 10); // 读取文件内容(阻塞直到数据就绪或流结束) |
转到了有多少个 CPU 核心。通过将串行转为并行,我们大大提升了系统的吞吐率。我们已经优化的很棒了,但是这里还有没有优化空间呢?当然有!
1、过量输入缓存。线程数最好不要超过 CPU 核心数过多,否则大量线程都是等待 CPU 的状态,存储这些线程的相关信息会占用大量的内存(线程栈1M、本地变量若干......,),因此我们可以选择适当新建线程,超过系统处理能力的请求,将其输入的参数缓存,待后续处理。
2、线程复用。每来一个 input ,我们都要新建线程、启动、销毁,这一套流程消耗太大了,我们可以考虑线程复用技术,通过向线程池提交不同的任务,动态地处理变化的参数,避免线程构造销毁的开销。
关于线程池的线程复用技术,可以阅读这篇博文来理解:https://juejin.cn/post/6844904205623246861
到这里,引用 [https://zhuanlan.zhihu.com/p/651946800] 的一句话来说,我们其实已经实现了一个 N (客户端请求数量)大于 M (服务端处理客户端请求的线程数量)的 I/O 模型。我们这里并没有引入 Socket ,而是使用了手动在命令行输入指令,代替多客户端同时连接,以更清晰简单地解释吞吐率的概念。
闲话:Socket 编程
回归 NIO
我们打开 java.nio 包后发现,这里面的类更是多的吓人。但是大部分的面经都很少描述 NIO 相关的内容,我们。
从 Linux 内核角度探秘 JDK NIO 文件读写本质 https://mp.weixin.qq.com/s?__biz=Mzg2MzU3Mjc3Ng==&mid=2247486623&idx=1&sn=0cafed9e89b60d678d8c88dc7689abda&chksm=ce77cad8f90043ceaaca732aaaa7cb692c1d23eeb6c07de84f0ad690ab92d758945807239cee&token=1276722624&lang=zh_CN#rd
2、启动一个线程,都做了什么?
1.2 JAVA 的线程
1 |
|

